John Stamatoyannopoulos, High Resolution Maps of Regulatory DNA
Top builders in biotech
Axial: https://linktr.ee/axialxyz
Axial partners with great founders and inventors. We invest in early-stage life sciences companies such as Appia Bio, Seranova Bio, Delix Therapeutics, Simcha Therapeutics, among others often when they are no more than an idea. We are fanatical about helping the rare inventor who is compelled to build their own enduring business. If you or someone you know has a great idea or company in life sciences, Axial would be excited to get to know you and possibly invest in your vision and company . We are excited to be in business with you — email us at info@axialvc.com
John Stamatoyannopoulos is a Professor of Genome Sciences and Medicine at the University of Washington and the director of the Altius Institute. Where his lab (known as Stam Lab for short), pioneers high-resolution, genome-scale mapping and analysis of transcriptional regulatory regions. Building structural mapping of protein-DNA contacts within human regulatory regions genome wide,and identifying functional non-coding polymorphisms that modulate quantitative traits and disease susceptibility.
As a lead of the ENCODE project, he helped publish key research from the consortium in 2012 establishing the significance of regulatory regions within the genome. ENCODE stands for ‘Encyclopedia of DNA Elements.’ Going to Stanford for college in 1990 studying biological sciences, symbolic systems, and classics, Stamatoyannopoulos then went to medical school at the UoW. Completing his residency at Brigham and Women's Hospital. After a fellowship at Dana Farber & MGH joining, and serving as CSO of Regulome, joining the Washington faculty in 2005.
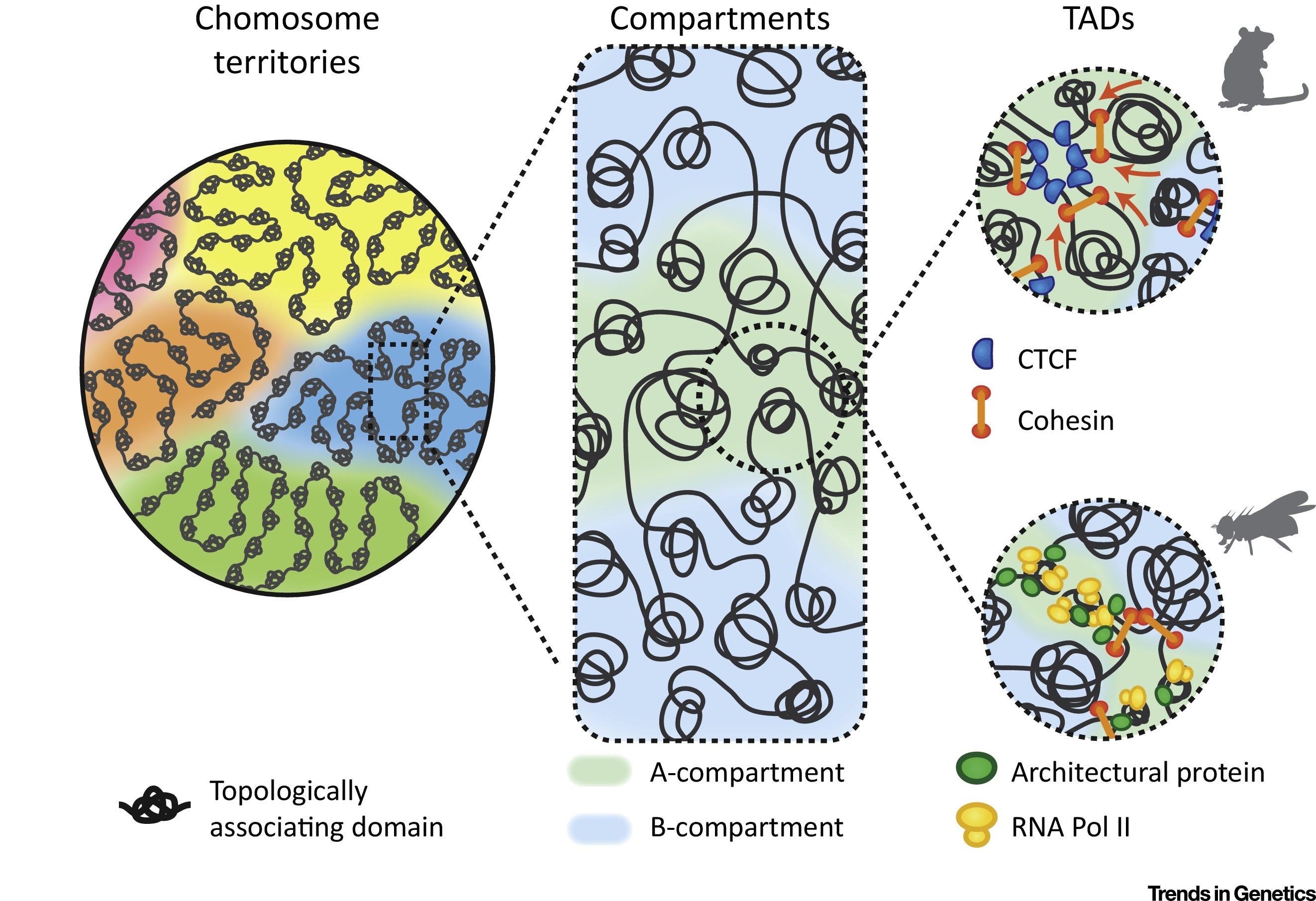
The Stam Lab uses high-throughput molecular & computational tools to decode the regulatory circuitry of the human and other complex genomes. And the functional consequnces of non-coding genetic variation:
Creating comprehensive atlases of regulatory DNA encoded in the human and mouse genomes
Defining regulatory networks that control cell fate and response. Mainly mapping transcription factor regulatory networks.
Identifying & characterizing human regulatory variants associated with common human diseases
Developing next-generation technologies for interrogating, interpreting, and programming the human regulatory genome. Particularly visualization technologies.
After the Human Genome Project completed the first draft of the sequenced human genome in 2003, it was found that 1%-2% of the genome encode for proteins. And the rest is purportedly non-coding. Perjoratively called junk DNA. The ENCODE project was immediately launched in 2003 after the first human genome was sequenced; to map out the ‘dark genome’ and understand the function of these regulatory, and maybe functional, elements. And by uncovering thr regulatory instructions in the genome beyond protein-coding genes, creating new ways to understand and treat disease. With companies like Talus Bio building on top of these initiatives to develop medicines taking into account how these regulatory elements influence health and disease.
There are 100Ks of regions in the genome that control gene expression, with more space dedicated to regulating genes than the genes themselves. In 2012, the ENCODE project’s first draft suggested that up to 80% of the non-coding genome has a function. This is heavily disputed with the low end being ~10%. Better measurement techniques like ATAC-seq have made genomic maps more accurate. Uncovering unmarked regulatory elements (URE) that captured by older, DNase-seq approaches. However, the main challenge is determining the function of many parts of the dark genome. Some parts (i.e. smORFs) actually encode for proteins where they weren’t originally expected too. Other parts play a role in the 3D genome and act at a ‘distance.’ While most elements still have no known function. There are millions of enhancers across the genome. Influencing the expression of genes thousands of base pairs away. It’s tough to predict which enhancers act on which genes purely from sequencing. You need functional & structural data.
Groups are now working to distinguish between functional and non-functional elements. However, the approach used for protein-coding genes might not work for the dark genome. For the former, you would delete each gene one at a time and observe the consequences in a cell assay or animal model. For the non-coding genome, the scale is >10x and many parts of it are redundant. Making one-by-one deletion not useful.
CRISPR systems have allowed groups to alter larger numbers of regulatory elements. Led by scientists like Neville Sanjana and Richard Sherwood, the field has been able to connect various enhancers to cancer targets like p53 and resistance to approved drugs. Steadily building out a functional dataset that will become sufficient to build predictive models of transcription-factor binding sites, enhancers, and even regions of the genome that influence its 3D structure. Potentially getting to the point where we can predict, or just know, the target genes for every regulatory element.